Hire Top 1% AI Engineers | 100% In-House Team
Ship production AI systems with engineers who've already done it. ScalaCode places senior AI developers, LLM specialists, agent architects, computer vision engineers, MLOps leads, and RAG engineers, pre-tested on real OpenAI, Anthropic, vLLM, and NVIDIA NIM deployments. Hire dedicated AI developers to take your AI roadmap from proof-of-concept to production outcome, at scale, in your perimeter.
Profiles tailored to your tech stack & timeline






Our AI engineering bench covers the full 2026 AI engineering stack. The role you need depends on the workload, and matching that correctly at the start is what determines whether the engagement ships in 8 weeks or 18 months.
Fine-tuning on LoRA, QLoRA, DPO, and RLHF; serving on vLLM, NVIDIA Triton, and NVIDIA NIM; eval-use design for golden test datasets; cost optimization at scale via smart routing, multi-LoRA serving, and speculative decoding. Our LLM engineers have shipped fine-tuned Llama 3.3, Qwen 3, Mistral, and DeepSeek deployments inside customer perimeters and across cloud-frontier APIs.
Multi-step autonomous workflows on the OpenAI Agents SDK, CrewAI, LangGraph, and AutoGen; MCP-native integrations across Salesforce, SAP, Snowflake, ServiceNow, GitHub, and 1,500+ enterprise systems; governance design including human-in-the-loop checkpoints, confidence routing, and compensating-action workflows for partial-completion scenarios. See our AI Agent Development service for full delivery context.
Vector pipelines on Pinecone, Weaviate, Qdrant, pgvector, and Milvus; hybrid retrieval combining BM25 with dense embeddings; reranker model integration; eval harnesses for grounding accuracy and hallucination rate; update workflows for enterprise content drift. See our RAG Development Services for the full delivery breakdown.
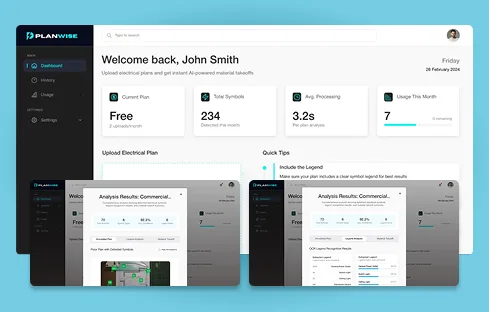
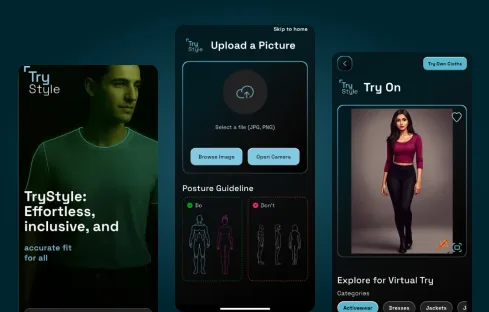
Image classification, object detection, OCR, video analysis, satellite/drone imagery, segmentation; PyTorch and TensorFlow model training; transfer-learning pipelines; production deployment with NVIDIA Triton inference servers. Real-world examples include Planwise’s electrical-takeoff CV and TryStyle’s iOS virtual try-on.
Entity extraction, document classification, intent recognition, summarization, voice transcription on Whisper, multilingual semantic search. See our NLP Development Services and Sentiment Analysis Solutions for the full delivery breakdown.
Feature stores (Tecton, Feast); model registries (MLflow, Weights & Biases); CI/CD for ML on GitHub Actions; drift monitoring (WhyLabs, Evidently, Arize); evaluation harnesses; retraining pipelines on Airflow, Prefect, or Dagster; production observability tied to SRE practice. The discipline most data-science teams don’t have but every production AI system needs.
Content generation, document drafting, voice synthesis with ElevenLabs, image and video generation; multi-model routing across GPT-5, Claude Sonnet 4.6, Gemini 2.5, Llama 3.3; safety guardrails on Llama Guard, NVIDIA NeMo Guardrails, and Lakera Guard. Visit Generative AI Development Services for the full delivery breakdown.
Demand forecasting, churn prediction, predictive maintenance, fraud-risk scoring; gradient boosting on XGBoost, LightGBM, CatBoost; time-series with Prophet and statsmodels; calibration and drift monitoring. Visit Predictive Analytics Solutions and AI Fraud Detection Solutions for a the full delivery breakdown .
Production prompt engineering, structured-output design, prompt-injection defense, model selection across the modern LLM landscape. Often paired with eval use design and cost-optimization workstreams.
clients served
country delivery footprint
AI models deployed to production
client retention rate
years in business
Those are marketplaces. You’re matched to a freelancer, then it’s your problem to manage. We’re a placement firm with senior architects on the engagement, full vetting we own end-to-end, and accountability for engineer success. If something doesn’t work, we replace; you don’t restart the search.
(Accenture, EPAM, Persistent, Fractal, GlobalLogic): they bring brand and scale. They also bring project-management overhead and 30-50% bench markup. We bring senior engineers without the management layer or the markup. Faster decisions, sharper engineers, less politics, at materially better unit economics for the same skill profile.
A 6-month timeline plus recruiter fees plus onboarding plus retention risk versus 48-hour placement with vetted talent and a built-in 1-week trial. In-house wins for permanent core capability you’ll need 5+ years. We win for time-to-shipped-outcome on bounded engagements and for capability you need to build now while the in-house plan plays out.
Our hire engagements connect to deeper service capabilities when you want full delivery, not just talent placement:
Submit your requirement via the form on this page. Tell us role, specialization, engagement type, and project context.
30-minute discovery call within 4 hours of submission. Our AI hiring lead aligns on requirements, timeline, technology constraints, and budget envelope. No sales theatre, just clarification questions and a shape of fit.
Shortlist of 2-3 candidates within 48 hours. Each candidate has cleared our 3-stage vetting (8.5% net pass rate). We share full profiles plus 30-min Loom intros so you don’t burn cycles on early-stage screens.
You interview the candidates. Technical interview, culture interview, project-context conversation, your call. We’re available throughout for context or follow-up vetting if you want depth on a specific area.
Onboarding within 1 week of selection. NDA, IP-assignment, security setup, infrastructure access, we handle the paperwork. Engineer ships first commit by end of week one.
Risk-free: 1-week trial period with full money-back guarantee if engagement quality doesn’t match the vetted profile.
Every AI engineer we present has cleared all three stages. Average vetting time per candidate is 14-22 hours of senior-engineer time. That's why our placement quality is what it is, and why the interview you run is the second screen, not the first.
Candidate designs a production AI system from a cold prompt, say, “build an AI agent for insurance claims triage.” Our senior architect probes architecture, model selection, eval design, cost economics, and failure handling. We’re looking for the difference between “knows the tools” and “knows what to build.” Pass rate: ~22%.
Candidate builds a small production-grade component, a data pipeline, an eval use, a RAG retrieval layer, on real infrastructure. We grade code quality, testing discipline, observability awareness, and willingness to ask the right clarifying questions. Pass rate of Stage 1 passers: ~55%.
Candidate audits an in-flight AI system we control and produces a remediation plan covering observability gaps, drift exposure, security and compliance issues, and cost optimization opportunities. This tests senior judgment beyond raw coding skill. Pass rate of Stage 2 passers: ~70%.
Net pass rate: ~8.5%. Every candidate you interview has cleared this gauntlet. We’re transparent about which stage each candidate cleared with what notes, no opaque “vetted” handwaving.
Hire structures matter as much as engineer skill. The four arrangements we use most often:
One of our engineers joins your team as a dedicated long-term resource, your stand-ups, your sprint cadence, your tools, your time zone. Standard for clients building permanent AI capability. Minimum 3-month engagement, typically 6-18 months. Mid-Level from $13/hr ($1,800/mo); Senior from $18/hr ($2,200/mo); Lead from $23/hr ($3,200/mo), all-inclusive of benefits, equipment, and infrastructure.
For time-bounded AI initiatives, build a recommender, ship an agent platform, deploy an LLM application. Includes architect plus engineers plus MLOps lead plus project lead. Typical scope: $80k-$500k over 8-24 weeks depending on complexity.
A senior engineer for a defined scope, calibration audit, eval use build, drift monitoring rollout, RAG retrieval-quality review. 4-12 weeks. Best when your in-house team is strong but needs depth in a specific area.
We run discovery and architecture then continue into delivery if you decide to build. De-risks engagement structure for first-time AI buyers and gives both sides a clean exit point if discovery surfaces something that changes the case.


(1-2 years experience, supervised work): $10-$12/hr
(3-5 years experience, ships independently): $13-$15/hr or $1,800-$2,100/month
(5+ years, designs systems, mentors mid-level): $18-$20/hr or $2,200-$3,000/month
(8+ years, leads programs, mentors senior): $23-$25/hr or $3,200-$4,000/month
All-inclusive, no markups for benefits, equipment, infrastructure, or “platform fees.” We don’t do hidden costs. Long-term engagement discounts available for 6-month-plus commitments.
Hourly rates step down with larger committed blocks (40 hrs / 80 hrs / 120 hrs per 30-day cycle). For team-augmentation engagements that include Junior or Associate engineers under senior supervision, additional bands run from $1,200/month (Associate) and $1,400/month (Junior).
The cost of a bad AI engineer hire isn’t just salary, it’s three to six months of model rewrites, infrastructure resets, and stakeholder confidence eroded by demos that don’t survive production. We’ve seen this pattern enough times to make it our problem to solve.
ScalaCode AI engineers come pre-tested on the work that breaks generic developers: building eval harnesses that catch silent regressions, designing confidence-routing for high-stakes decisions, integrating LLMs into existing enterprise stacks without breaking compliance, and shipping models that survive adversarial pressure. Our 3-stage vetting process is what an in-house hiring loop wishes it had, AI systems design interview, live engineering challenge on real workflows, and a production-readiness exercise covering observability, drift monitoring, and cost economics.
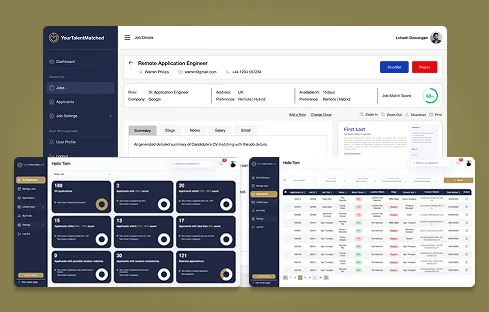
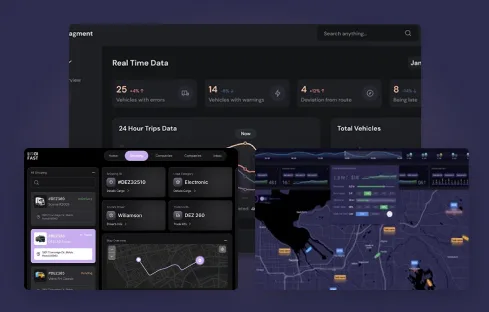
Every engineer we place has shipped at least one production AI system. Most have shipped three to seven. Across our team we’ve delivered LLM, agent, RAG, computer vision, and MLOps engagements to clients across 45+ countries, including AI builds for HR tech (Talent Matched), construction-AEC (Planwise), logistics (Fleet Optimization, Predictive Maintenance), fashion eCommerce (TryStyle), and tourism (AI Reputation Platform).
Marketplaces match you to a freelancer, then it’s your problem. We’re a placement firm with full ownership of vetting, senior architects available on every engagement, and accountability if engineer fit isn’t right. Our 3-stage vetting (AI systems design / live engineering / production-readiness) has an 8.5% net pass rate. Every candidate we present has been pre-tested by our senior engineering team, your interview is the second screen, not the first. If an engagement underperforms in the first week, we replace at no cost.
48 hours from requirement submission to shortlist of 2-3 vetted candidates. Onboarding (NDA, IP-assignment, security setup, infrastructure access) takes another 3-5 business days. Engineer typically ships first commit by end of week one. End-to-end: 7-10 days from “tell me what you need” to “engineer is shipping code.” For specialist roles (RAG architects, MLOps leads with specific cloud certifications), the shortlist may take 5-7 days because the bench is smaller and we won’t pad with poor matches.
Mid-Level AI Engineer (3-5 yrs): $13-$15/hr or $1,800-$2,100/mo. Senior AI Engineer (5+ yrs): $18-$20/hr or $2,200-$3,000/mo. Lead Engineer (8+ yrs): $23-$25/hr or $3,200-$4,000/mo. Hourly rates step down with larger committed blocks (40/80/120 hours per 30-day cycle). All-inclusive, no markups for benefits, equipment, infrastructure, or “platform fees.” A typical 3-engineer Stage-2 AI engagement over 12 weeks delivers comparable engineering depth at meaningfully below Big-4 SI rates. Discovery sprints from $15k. Long-term commitment discounts available on 6-month-plus engagements.
Yes. We staff for time-zone match, US East / US West / UK / EU / APAC / Australia all supported. Most of our engineers work overlapping hours with their primary client time zone. For US-East clients we typically run 4-6 hours of overlap; for US-West, 3-5 hours. Full-time embedded engineers can match your stand-up cadence directly. We don’t do “we’ll respond tomorrow” delivery, async-first with clear SLA on response time, plus live overlap windows for collaboration.
1-week risk-free trial, if quality doesn’t match the vetted profile, full refund and we restart the placement. Beyond week one, if performance issues arise we replace at no cost within 5 business days. Our retention rate on completed engagements is 92% (engagement runs to planned end with the same engineer); the remaining 8% are typically scope changes mid-engagement requiring a different specialization, not performance failures. We track this metric publicly for our placement firm credibility.
Yes. Every engagement starts with mutual NDA before we share any candidate profiles. IP assignment is built into our standard contract, all code, models, data artifacts, and documentation produced during the engagement become your property. We carry professional liability insurance covering both data security and IP-assignment risk. For regulated workloads (BFSI, healthcare, defense), we layer additional controls, background checks on engineers, isolated infrastructure, audit logging, and have shipped under SR 11-7, HIPAA, and India MeitY constraints.
Yes. We’ve staffed engineers for AWS GovCloud, Azure Government, India MeitY-empanelled regions, and fully on-premises bank and government deployments. Open-source model expertise (Llama 3.3, Qwen 3, Mistral, DeepSeek) is part of our standard bench so air-gapped LLM deployments don’t require specialist sourcing. For defense and intelligence workloads we maintain a separately-cleared engineering pool, not all our engineers qualify, but the ones who do have shipped under those constraints.
4-week fractional engagement at $15k for a defined-scope deliverable (calibration audit, eval use build, drift monitoring rollout, RAG retrieval-quality review). For embedded engineers we ask for a 3-month minimum so onboarding investment is recovered. Below 4 weeks, the back-and-forth ratio doesn’t work, we’ll usually recommend a different vendor or in-house freelancer for those scopes rather than take engagements where we can’t deliver value.
Discovery call. We ask: what’s the workload (text / image / voice / multi-modal / structured data), what’s the buyer audience (consumer / enterprise / regulator), what’s the latency profile (batch / real-time / sub-50ms), what’s the deployment substrate (frontier API / on-prem / air-gapped / hybrid), and what’s the success metric (accuracy / speed / cost-per-call / regulator-readiness). Those five answers narrow the role from “AI engineer” to one of LLM / Agent / RAG / CV / NLP / MLOps / GenAI / Predictive ML / Prompt Strategist. Wrong-role placement is the single most common reason AI engagements miss timelines, and matching it correctly at the start saves months downstream.
Yes. After 6 months of embedded engagement, we offer a structured conversion path, engineer transitions to your direct payroll with a one-time conversion fee (typically 15-25% of annual salary depending on engagement length). We support the transition rather than block it; long-term retention with great clients is good for our reputation and for the engineer. For engagements shorter than 6 months, conversion fees scale up. Worth flagging upfront if hire-to-permanent is your eventual goal so we structure the engagement accordingly.

They bridged the time-zone gap effortlessly and always went the extra mile, exactly what I needed for a responsive tech partner.
Recognized by Industry Leaders & Valued by Global Clients





